Lustre Filesystem Benchmarks
FIO
Examples
Small sequential writes:
fio --numjobs=64 --name=seq_write_$(hostname) --iodepth=16 --size=16g --blocksize=128k --direct=1 --ioengine=libaio --rw=write --directory=/mnt/cstor1/ccarlson/flash --group_reporting --output-format=json --output=seq_write_small.jsonLarge sequential writes:
fio --numjobs=64 --name=seq_write_$(hostname) --iodepth=2 --size=16g --blocksize=16m --direct=1 --ioengine=libaio --rw=write --directory=/mnt/cstor1/ccarlson/flash --group_reporting --output-format=json --output=seq_write_large.jsonLarge sequential reads:
fio --numjobs=64 --name=seq_read_$(hostname) --size=16g --blocksize=64m --ioengine=libaio --rw=read --directory=/mnt/cstor1/ccarlson/flash --group_reporting --output-format=json --output=seq_read_large.jsonIOR
Documentation:
Installation
Stop your firewall, this can prevent openmpi communication:
systemctl stop firewalld
setenforce 0Install openmpi for your distribution:
Clone the ior repo:
git clone https://github.com/hpc/ior
cd ior/Next, bootstrap, configure and make the IOR software:
./bootstrap
./configure
makeAdd the built ior binary to your PATH variable:
export PATH="$PATH:$HOME/ior/src/ior"Usage
-
Login to one of the compute nodes as the benchmark user
-
Create a host file for the
mpiruncommand, containing the list of Lustre clients that will be used for the benchmark. Each line in the file represents a machine and the number of slots (usually equal to the number of CPU cores). For example:for i in $(seq -f "%02g" 1 4); do echo "n"$i" slots=128" done > $HOME/hostfileThis results in a file like the following:
n01 slots=128 n02 slots=128 n03 slots=128 n04 slots=128-
The first column of the host file contains the name of the nodes. This can also be an IP address if the /etc/hosts file or DNS is not set up.
-
The second column is used to represent the number of CPU cores.
-
-
Run a quick test using
mpirunto launch the benchmark and verify that the environment is set up correctly. For example:mpirun --hostfile $HOME/hostfile --map-by node -np $(cat $HOME/hostfile | wc -l) hostname
If this is working, you can move on to using the IOR tool. I use the following benchmark.sh script to make benchmarks easier
to execute by just changing some variables:
#!/bin/bash
set -ex
IOR_BIN="/home/ccarlson/ior/src/ior"
MACHINE_FILE="machinefile.txt"
TOTAL_HOSTS=$(cat $MACHINE_FILE | wc -l)
THREADS_PER_NODE=(1 8 16 32 64 128)
BLOCKSIZE_PER_TASK="16g"
TRANSFER_SIZES=("128k" "1m" "16m" "64m")
TEST_DIRECTORY="/mnt/cstor1/ccarlson/flash"
TEST_FILE="testfile"
# Sequential Write
function seq_write {
TRANSFER_SIZE=$1
THREADS=$2
OUT_FILE="$OUT_DIR/seq_write_${TRANSFER_SIZE}_${THREADS}.csv"
mpirun --allow-run-as-root --machinefile $MACHINE_FILE --mca btl_tcp_if_include eth0 -np $(( THREADS * TOTAL_HOSTS )) --map-by "node" \
$IOR_BIN -v -F --posix.odirect -C -t $TRANSFER_SIZE -b $BLOCKSIZE_PER_TASK -e -w -k -o $TEST_DIRECTORY/$TEST_FILE \
-O summaryFile=$OUT_FILE -O summaryFormat=CSV
RESULTS=$(tail -1 $OUT_FILE)
echo -e "seq_write,$THREADS,$TRANSFER_SIZE,$RESULTS" >> $OUT_DIR/results.csv
}
# Random Write
function rand_write {
TRANSFER_SIZE=$1
THREADS=$2
OUT_FILE="$OUT_DIR/rand_write_${TRANSFER_SIZE}_${THREADS}.csv"
mpirun --allow-run-as-root --machinefile $MACHINE_FILE --mca btl_tcp_if_include eth0 -np $(( THREADS * TOTAL_HOSTS )) --map-by "node" \
$IOR_BIN -v -F --posix.odirect -C -t $TRANSFER_SIZE -b $BLOCKSIZE_PER_TASK -e -w -z -k -o $TEST_DIRECTORY/$TEST_FILE \
-O summaryFile=$OUT_FILE -O summaryFormat=CSV
RESULTS=$(tail -1 $OUT_FILE)
echo -e "rand_write,$THREADS,$TRANSFER_SIZE,$RESULTS" >> $OUT_DIR/results.csv
}
# Sequential Read
function seq_read {
TRANSFER_SIZE=$1
THREADS=$2
OUT_FILE="$OUT_DIR/seq_read_${TRANSFER_SIZE}_${THREADS}.csv"
mpirun --allow-run-as-root --machinefile $MACHINE_FILE --mca btl_tcp_if_include eth0 -np $(( THREADS * TOTAL_HOSTS )) --map-by "node" \
$IOR_BIN -v -F --posix.odirect -C -t $TRANSFER_SIZE -b $BLOCKSIZE_PER_TASK -r -k -o $TEST_DIRECTORY/$TEST_FILE \
-O summaryFile=$OUT_FILE -O summaryFormat=CSV
RESULTS=$(tail -1 $OUT_FILE)
echo -e "seq_read,$THREADS,$TRANSFER_SIZE,$RESULTS" >> $OUT_DIR/results.csv
}
# Random Read
function rand_read {
TRANSFER_SIZE=$1
THREADS=$2
OUT_FILE="$OUT_DIR/rand_read_${TRANSFER_SIZE}_${THREADS}.csv"
mpirun --allow-run-as-root --machinefile $MACHINE_FILE --mca btl_tcp_if_include eth0 -np $(( THREADS * TOTAL_HOSTS )) --map-by "node" \
$IOR_BIN -v -F --posix.odirect -C -t $TRANSFER_SIZE -b $BLOCKSIZE_PER_TASK -r -z -k -o $TEST_DIRECTORY/$TEST_FILE \
-O summaryFile=$OUT_FILE -O summaryFormat=CSV
RESULTS=$(tail -1 $OUT_FILE)
echo -e "rand_read,$THREADS,$TRANSFER_SIZE,$RESULTS" >> $OUT_DIR/results.csv
}
[ $# -ne 1 ] && echo -e "Usage:\n\tbenchmark.sh <output_directory>\n" && exit 1
OUT_DIR=$1
mkdir -p $OUT_DIR
echo -e "access_type,threads,transfer_size,access,bw(MiB/s),IOPS,Latency,block(KiB),xfer(KiB),open(s),wr/rd(s),close(s),total(s),numTasks,iter" \
> $OUT_DIR/results.csv
for THREADS in ${THREADS_PER_NODE[@]}; do
for TRANSFER_SIZE in ${TRANSFER_SIZES[@]}; do
echo -e "\nRunning benchmark with transfer size of $TRANSFER_SIZE, and $THREADS threads\n"
seq_write $TRANSFER_SIZE $THREADS
seq_read $TRANSFER_SIZE $THREADS
rand_write $TRANSFER_SIZE $THREADS
rand_read $TRANSFER_SIZE $THREADS
done
doneYou can use this by just running ./benchmark.sh <output_directory>, i.e:
./benchmark.sh /home/ccarlson/multi_nodeThis will collect all your aggregated CSV results into a single results.csv file, a snippet of which looks like:
access_type,threads,transfer_size,access,bw(MiB/s),IOPS,Latency,block(KiB),xfer(KiB),open(s),wr/rd(s),close(s),total(s),numTasks,iter
seq_write,32,16m,write,27135.9688,1696.0195,0.0363,16777216.0000,16384.0000,0.0086,38.6411,24.2267,38.6416,64,0
seq_read,32,16m,read,28805.2367,1800.3649,0.0355,16777216.0000,16384.0000,0.0016,36.4015,24.7580,36.4023,64,0
rand_write,32,16m,write,37879.2400,2367.4950,0.0257,16777216.0000,16384.0000,0.0114,27.6816,2.0832,27.6821,64,0
rand_read,32,16m,read,39275.2087,2454.7904,0.0257,16777216.0000,16384.0000,0.0017,26.6972,3.4322,26.6982,64,0
seq_write,32,64m,write,41838.6043,653.7421,0.0746,16777216.0000,65536.0000,0.0090,25.0619,6.8782,25.0624,64,0
seq_read,32,64m,read,43203.6925,675.0791,0.0912,16777216.0000,65536.0000,0.0015,24.2697,7.1871,24.2705,64,0
rand_write,32,64m,write,40580.2781,634.0792,0.0908,16777216.0000,65536.0000,0.1828,25.8390,8.8996,25.8395,64,0
rand_read,32,64m,read,43326.2159,676.9922,0.0713,16777216.0000,65536.0000,0.0024,24.2012,7.6495,24.2019,64,0Usage Example
The following example uses mpirun to execute a single instance (-np 1) of ior on the machine provided in machinefile.txt, mapped by slots available on that machine.
IOR is doing a sequential write (-w) benchmark, using file-per-process (-F), bypasses the hosts buffer with ODIRECT=1 flag (--posix.odirect=1), reordering tasks (-C),
with a transfer size of 128 KiB at a time (-t 128k), and a total block size of 16 GiB (-b 16g) per process. It does an fsync after the write operation is closed (-e), and keeps the files it wrote (-k). The output files go to /mnt/cstor1/ccarlson/testfile.XXXX where XXXX is the process ID. Finally, the benchmark summary is output to the file
single_node/slots_1/seq_write_128k.csv in the CSV format.
mpirun --allow-run-as-root --machinefile machinefile.txt -np 1 --map-by slot \
/home/ccarlson/ior/src/ior -v \
-F --posix.odirect -C -t 128k -b 16g -e -w -k \
-o /mnt/cstor1/ccarlson/testfile \
-O summaryFile=single_node/slots_1/seq_write_128k.csv \
-O summaryFormat=CSVCommand-line Options
| Option | Description |
|---|---|
-a S |
api - API for I/O [POSIX|MPIIO|HDF5|HDFS|S3|S3_EMC|NCMPI|RADOS] |
-A N |
refNum - user reference number to include in long summary |
-b N |
blockSize - contiguous bytes to write per task (e.g.: 8, 4k, 2m, 1g) |
-c |
collective - collective I/O |
-C |
reorderTasksConstant - changes task ordering to n+1 ordering for readback |
-d N |
interTestDelay - delay between reps in seconds |
-D N |
deadlineForStonewalling - seconds before stopping write or read phase |
-e |
fsync - perform fsync upon POSIX write close |
-E |
useExistingTestFile - do not remove test file before write access |
-f S |
scriptFile - test script name |
-F |
filePerProc - file-per-process |
-g |
intraTestBarriers - use barriers between open, write/read, and close |
-G N |
setTimeStampSignature - set value for time stamp signature |
-h |
showHelp - displays options and help |
-H |
showHints - show hints |
-i N |
repetitions - number of repetitions of test |
-I |
individualDataSets - datasets not shared by all procs [not working] |
-j N |
outlierThreshold - warn on outlier N seconds from mean |
-J N |
setAlignment - HDF5 alignment in bytes (e.g.: 8, 4k, 2m, 1g) |
-k |
keepFile - don’t remove the test file(s) on program exit |
-K |
keepFileWithError - keep error-filled file(s) after data-checking |
-l |
data packet type- type of packet that will be created [offset|incompressible|timestamp|o|i|t] |
-m |
multiFile - use number of reps (-i) for multiple file count |
-M N |
memoryPerNode - hog memory on the node (e.g.: 2g, 75%) |
-n |
noFill - no fill in HDF5 file creation |
-N N |
numTasks - number of tasks that should participate in the test |
-o S |
testFile - full name for test |
-O S |
string of IOR directives (e.g. -O checkRead=1,GPUid=2) |
-p |
preallocate - preallocate file size |
-P |
useSharedFilePointer - use shared file pointer [not working] |
-q |
quitOnError - during file error-checking, abort on error |
-Q N |
taskPerNodeOffset for read tests use with -C & -Z options (-C constant N, -Z at least N) [!HDF5] |
-r |
readFile - read existing file |
-R |
checkRead - check read after read |
-s N |
segmentCount - number of segments |
-S |
useStridedDatatype - put strided access into datatype [not working] |
-t N |
transferSize - size of transfer in bytes (e.g.: 8, 4k, 2m, 1g) |
-T N |
maxTimeDuration - max time in minutes to run tests |
-u |
uniqueDir - use unique directory name for each file-per-process |
-U S |
hintsFileName - full name for hints file |
-v |
verbose - output information (repeating flag increases level) |
-V |
useFileView - use MPI_File_set_view |
-w |
writeFile - write file |
-W |
checkWrite - check read after write |
-x |
singleXferAttempt - do not retry transfer if incomplete |
-X N |
reorderTasksRandomSeed - random seed for -Z option |
-Y |
fsyncPerWrite - perform fsync after each POSIX write |
-z |
randomOffset - access is to random, not sequential, offsets within a file |
-Z |
reorderTasksRandom - changes task ordering to random ordering for readback |
-
S is a string, N is an integer number.
-
For transfer and block sizes, the case-insensitive K, M, and G suffices are recognized. I.e.,
4kor4Kis accepted as 4096.
Case Study: Grenoble System Benchmark Results
Here we show a demo of the benchmark results captured using the aforementioned tools on the flash pool of a single ClusterStor E1000.
Single-node Performance
MPI parameters:
-
Number of processes: 1, 16, 32, 64, 128
-
Nodes: 1
-
Map-by: slots on node (node capable of 128 slots)
IOR write parameters:
-
File-per-process (
-F) -
POSIX write directives: O_DIRECT (
--posix.odirect) -
Transfer sizes: 128k, 1m, 16m, 64m (
-t N) -
Blocksize per task: 16g (
-b N) -
Invoke fsync on POSIX write close (
-e) -
Keep written files for reading later (
-k)
Additionally, the -z flag was used for the random writes test to write to random offsets.
IOR read parameters:
-
File-per-process (
-F) -
Transfer sizes: 128k, 1m, 16m, 64m (
-t N) -
Shift reads to what our node didn’t write, if we have neighboring nodes (
-C) -
Blocksize per task: 16g (
-b N)
Additionally, the -z flag was used for the random reads test to read from random offsets.
Single-node Plotted Results
Visualizing these results with matplotlib shows us some critical information:
Figure 1: Single-node write throughput: Write performance varies by concurrent thread count, categorized by transfer size.
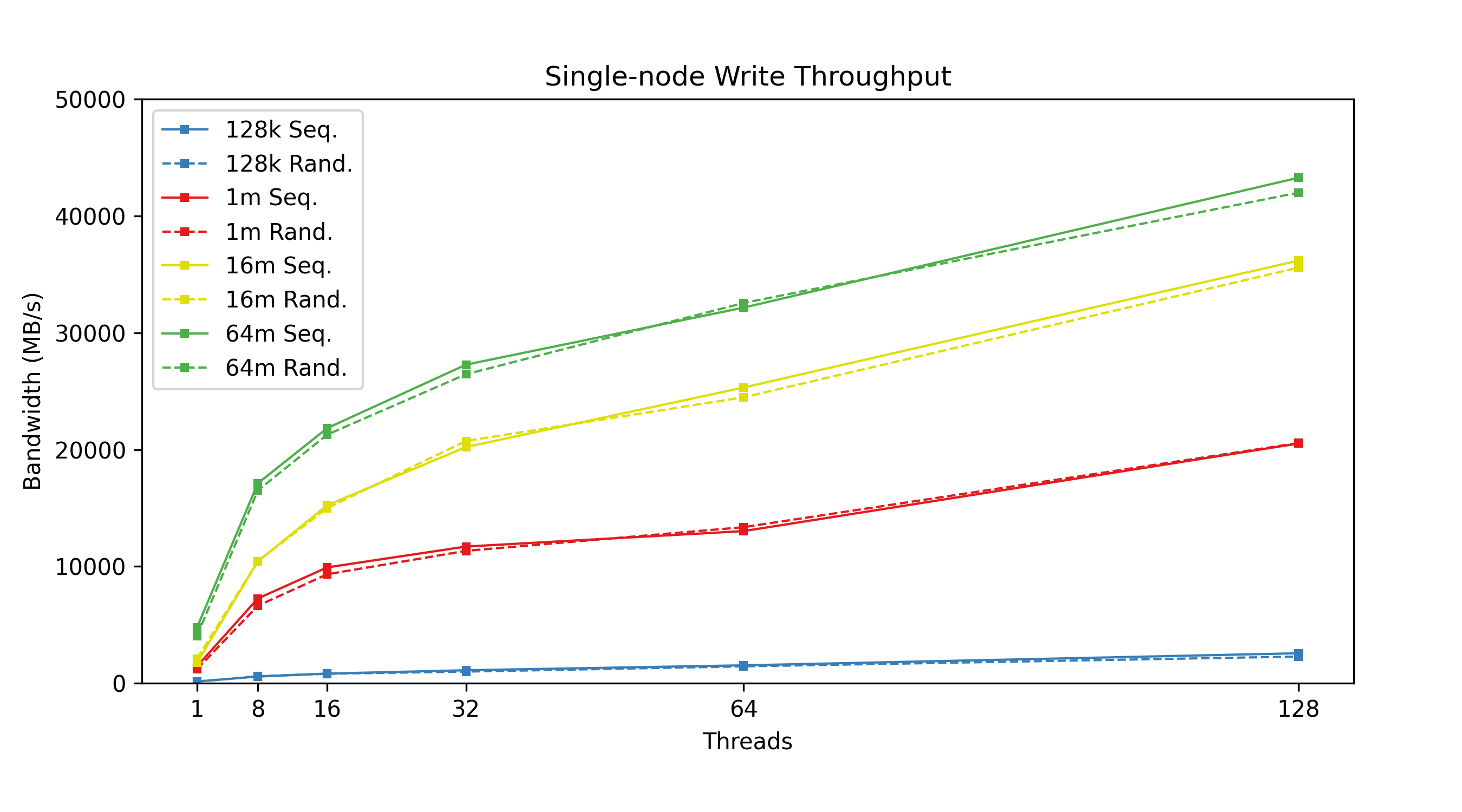
Figure 2: Single-node write IOPS: Write performance varies by concurrent thread count, categorized by transfer size.
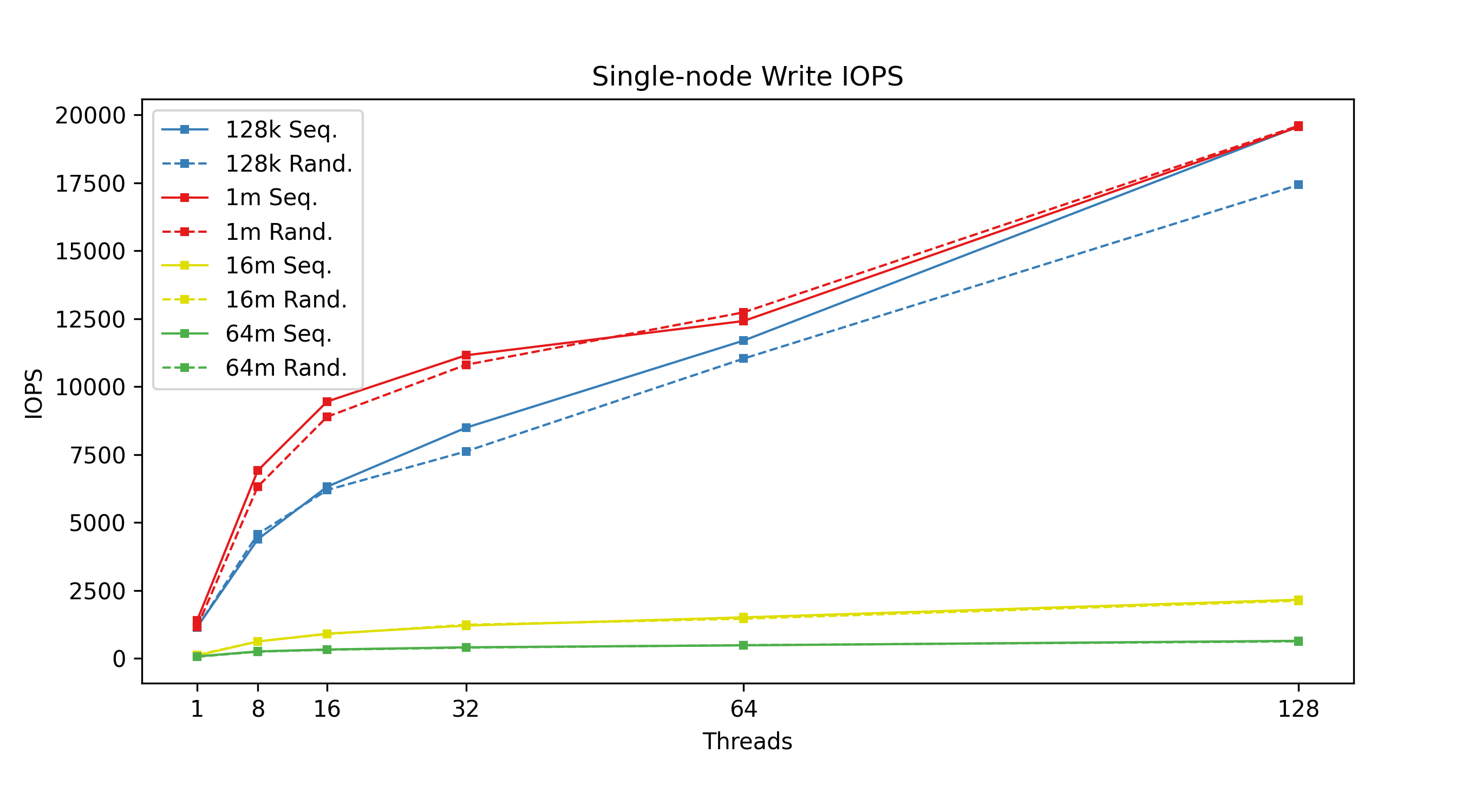
Figure 3: Single-node read throughput: Read performance varies by concurrent thread count, categorized by transfer size.
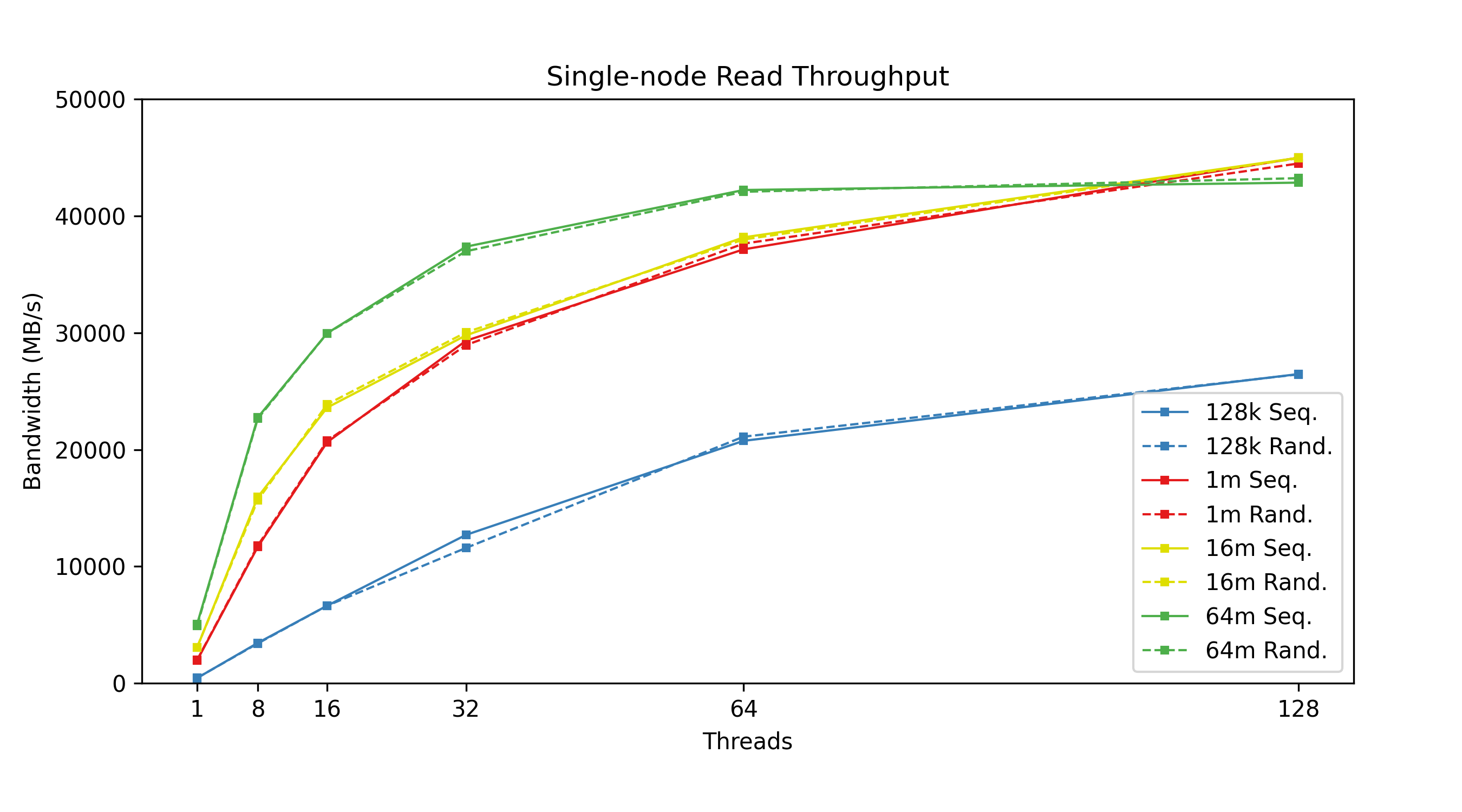
Figure 4: Single-node read IOPS: Read performance varies by concurrent thread count, categorized by transfer size.
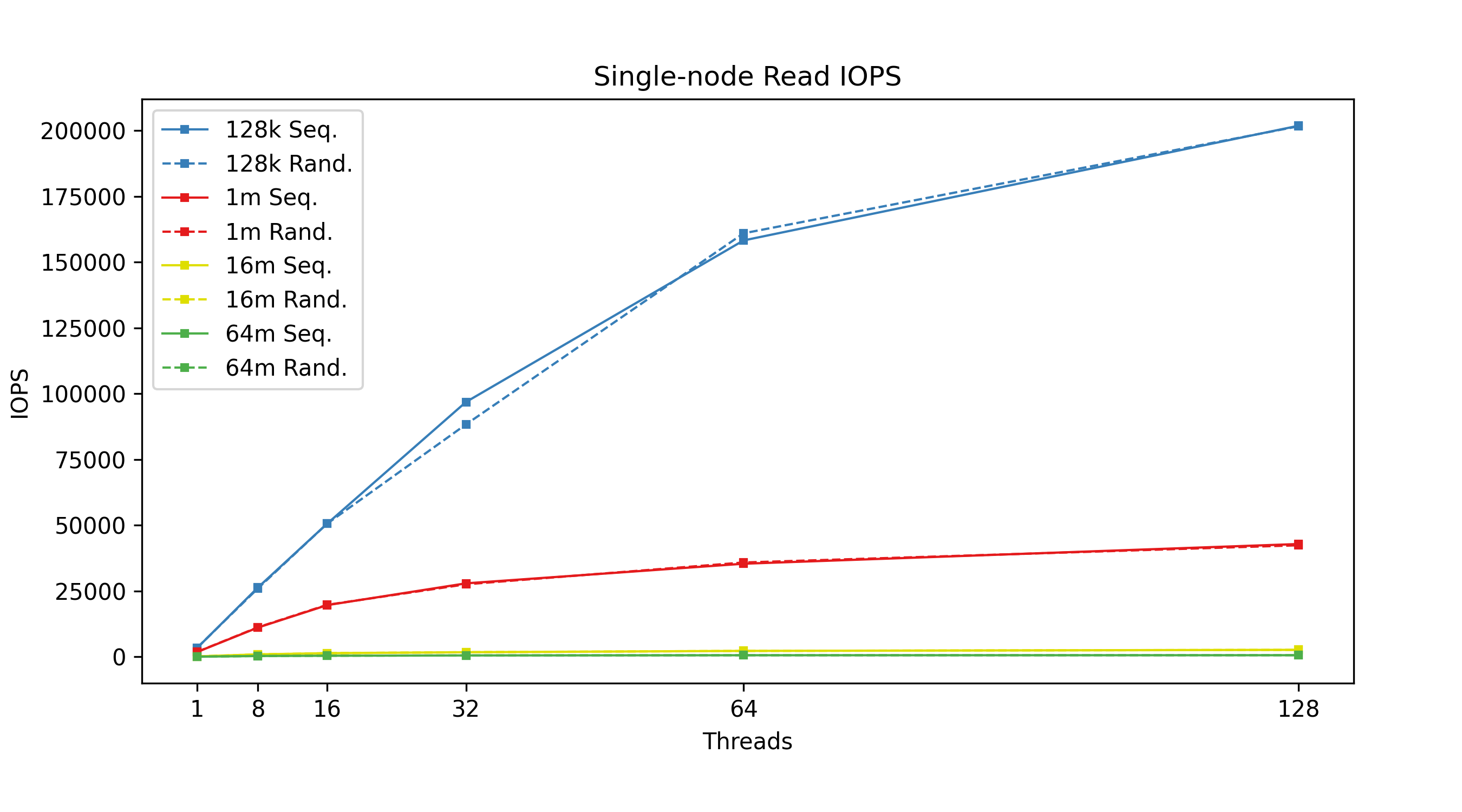
From the figures above, we can see that transfer size is inversely correlated with IOPS; the bigger your transfers are, the fewer you can do per second. Lustre has higher throughput with larger transfer sizes, meaning higher throughput means lower IOPS. We can also see the effects of having tuned the system for large I/O transfer sizes, in our case, 64 MiB transfer sizes. Trying to use smaller 128 KiB transfer sizes with a system tuned this way simply does not perform well when it comes to write throughput. Another curious discovery is that 1 MiB transfer sizes actually beat 128 KiB transfer sizes in terms of IOPS; a theory here is that Lustre queues up several 128 KiB transactions before sending, whereas 1 MiB transactions are sent immediately. Again, this is a tuning option that can be configured differently based on the user’s needs.
MDTest
MDTest Installation
Make sure MPI is installed on your nodes:
apt install openmpi-common=4.1.2-2ubuntu1 openmpi-bin=4.1.2-2ubuntu1 mpich=4.0-3 mpi-default-dev=1.14 libopenmpi3=4.1.2-2ubuntu1 libopenmpi-dev=4.1.2-2ubuntu1 libmpich12=4.0-3 libmpich-dev=4.0-3 libcaf-openmpi-3=2.9.2-3Then, clone the ior repo and make it to generate the mdtest binary
git clone https://github.com/hpc/ior.git && cd ior && ./bootstrap && ./configure && make && make installMDTest Synopsis
Synopsis mdtest
Flags
-C only create files/dirs
-T only stat files/dirs
-E only read files/dir
-r only remove files or directories left behind by previous runs
-D perform test on directories only (no files)
-F perform test on files only (no directories)
-k use mknod to create file
-L files only at leaf level of tree
-P print rate AND time
--print-all-procs all processes print an excerpt of their results
-R random access to files (only for stat)
-S shared file access (file only, no directories)
-c collective creates: task 0 does all creates
-t time unique working directory overhead
-u unique working directory for each task
-v verbosity (each instance of option increments by one)
-X, --verify-read Verify the data read
--verify-write Verify the data after a write by reading it back immediately
-y sync file after writing
-Y call the sync command after each phase (included in the timing; note it causes all IO to be flushed from your node)
-Z print time instead of rate
--warningAsErrors Any warning should lead to an error.
--showRankStatistics Include statistics per rank
Optional arguments
-a=STRING API for I/O [POSIX|DUMMY]
-b=1 branching factor of hierarchical directory structure
-d=./out directory or multiple directories where the test will run [dir|dir1@dir2@dir3...]
-B=0 no barriers between phases
-e=0 bytes to read from each file
-f=1 first number of tasks on which the test will run
-G=-1 Offset for the data in the read/write buffer, if not set, a random value is used
-i=1 number of iterations the test will run
-I=0 number of items per directory in tree
-l=0 last number of tasks on which the test will run
-n=0 every process will creat/stat/read/remove # directories and files
-N=0 stride # between tasks for file/dir operation (local=0; set to 1 to avoid client cache)
-p=0 pre-iteration delay (in seconds)
--random-seed=0 random seed for -R
-s=1 stride between the number of tasks for each test
-V=0 verbosity value
-w=0 bytes to write to each file after it is created
-W=0 number in seconds; stonewall timer, write as many seconds and ensure all processes did the same number of operations (currently only stops during create phase and files)
-x=STRING StoneWallingStatusFile; contains the number of iterations of the creation phase, can be used to split phases across runs
-z=0 depth of hierarchical directory structure
--dataPacketType=t type of packet that will be created [offset|incompressible|timestamp|random|o|i|t|r]
--run-cmd-before-phase=STRING call this external command before each phase (excluded from the timing)
--run-cmd-after-phase=STRING call this external command after each phase (included in the timing)
--saveRankPerformanceDetails=STRINGSave the individual rank information into this CSV file.
Module POSIX
Flags
--posix.odirect Direct I/O Mode
--posix.rangelocks Use range locks (read locks for read ops)
Module DUMMY
Flags
--dummy.delay-only-rank0 Delay only Rank0
Optional arguments
--dummy.delay-create=0 Delay per create in usec
--dummy.delay-close=0 Delay per close in usec
--dummy.delay-sync=0 Delay for sync in usec
--dummy.delay-xfer=0 Delay per xfer in usec
Module MPIIO
Flags
--mpiio.showHints Show MPI hints
--mpiio.preallocate Preallocate file size
--mpiio.useStridedDatatype put strided access into datatype
--mpiio.useFileView Use MPI_File_set_view
Optional arguments
--mpiio.hintsFileName=STRING Full name for hints file
Module MMAP
Flags
--mmap.madv_dont_need Use advise don't need
--mmap.madv_pattern Use advise to indicate the pattern random/sequentialMDTest Usage
Create a machinefile.txt for the nodes you want to use in the test:
o186i221 slots=128Here’s the template of the script I’m using to run the benchmarks:
set -ex
MDTEST_BIN=mdtest
TEST_DIRECTORY="/mnt/cstor1/ccarlson/flash"
mpirun --allow-run-as-root --machinefile machinefile.txt --mca btl_tcp_if_include eth0 -np 256 --map-by "node" $MDTEST_BIN -n 1024 -i 8 -u -d $TEST_DIRECTORYSingle-node results:
SUMMARY rate (in ops/sec): (of 1 iterations)
Operation Max Min Mean Std Dev
--------- --- --- ---- -------
Directory creation 45516.799 45516.799 45516.799 0.000
Directory stat 91325.356 91325.356 91325.356 0.000
Directory rename 19092.439 19092.439 19092.439 0.000
Directory removal 46454.459 46454.459 46454.459 0.000
File creation 27546.829 27546.829 27546.829 0.000
File stat 100070.848 100070.848 100070.848 0.000
File read 31330.659 31330.659 31330.659 0.000
File removal 47469.422 47469.422 47469.422 0.000
Tree creation 160.929 160.929 160.929 0.000
Tree removal 114.180 114.180 114.180 0.000Adding a node to the machinefile.txt:
o186i221 slots=128
o186i222 slots=128And running mdtest with -np 64 across two nodes:
SUMMARY rate (in ops/sec): (of 1 iterations)
Operation Max Min Mean Std Dev
--------- --- --- ---- -------
Directory creation 78491.020 78491.020 78491.020 0.000
Directory stat 171977.979 171977.979 171977.979 0.000
Directory rename 18771.272 18771.272 18771.272 0.000
Directory removal 74219.955 74219.955 74219.955 0.000
File creation 47604.781 47604.781 47604.781 0.000
File stat 203713.008 203713.008 203713.008 0.000
File read 57480.862 57480.862 57480.862 0.000
File removal 90014.367 90014.367 90014.367 0.000
Tree creation 126.758 126.758 126.758 0.000
Tree removal 77.215 77.215 77.215 0.000For mdtest with -np 96 across three nodes:
SUMMARY rate (in ops/sec): (of 1 iterations)
Operation Max Min Mean Std Dev
--------- --- --- ---- -------
Directory creation 97702.454 97702.454 97702.454 0.000
Directory stat 207674.088 207674.088 207674.088 0.000
Directory rename 18211.999 18211.999 18211.999 0.000
Directory removal 81427.460 81427.460 81427.460 0.000
File creation 66567.553 66567.553 66567.553 0.000
File stat 230463.001 230463.001 230463.001 0.000
File read 69500.465 69500.465 69500.465 0.000
File removal 110073.006 110073.006 110073.006 0.000
Tree creation 127.715 127.715 127.715 0.000
Tree removal 59.439 59.439 59.439 0.000And lastly, mdtest with -np 128 across four nodes:
SUMMARY rate (in ops/sec): (of 8 iterations)
Operation Max Min Mean Std Dev
--------- --- --- ---- -------
Directory creation 84251.208 62647.619 78386.218 6880.651
Directory stat 361536.604 332163.887 352341.756 10178.275
Directory rename 18698.508 17422.244 18151.485 452.181
Directory removal 105595.415 88066.194 98551.598 7980.985
File creation 70881.893 57927.137 63400.068 4959.008
File stat 454551.577 436691.911 445087.492 5121.937
File read 82874.429 77116.916 80370.560 2020.437
File removal 129379.591 106346.752 118982.552 10990.342
Tree creation 83.131 55.279 78.752 9.537
Tree removal 43.141 40.316 41.821 0.997LNet Self-Test (lst)
On huygens, nid509 to 510 1:1 BW:
WRITES:
nid509:~ # lst.sh -f 9027@kfi -t 9026@kfi -d 1:1 -m write -c 32 -n 1 -C simple
Discover server NIDs
Discover client NIDs
Start LST write - Fri 15 Nov 2024 12:42:31 PM CST
LST_SESSION=225181
SESSION: lnet_session FEATURES: 1 TIMEOUT: 300 FORCE: No
Adding clients: 9027@kfi
9027@kfi are added to session
Adding servers: 9026@kfi
9026@kfi are added to session
Test: --batch brw_write --concurrency 32 --from clients --to servers --distribute 1:1 brw write check=simple size=1m
Stat: --count 1 --delay 15 --bw --mbs clients servers
Test was added successfully
brw_write is running now
[LNet Bandwidth of clients]
[R] Avg: 5.83 MB/s Min: 5.83 MB/s Max: 5.83 MB/s
[W] Avg: 38216.58 MB/s Min: 38216.58 MB/s Max: 38216.58 MB/s
[LNet Bandwidth of servers]
[R] Avg: 38215.57 MB/s Min: 38215.57 MB/s Max: 38215.57 MB/s
[W] Avg: 5.83 MB/s Min: 5.83 MB/s Max: 5.83 MB/s
1 batch in stopping
Batch is stopped
Stop LST write - Fri 15 Nov 2024 12:42:47 PM CST
session is endedREADS:
nid509:~ # lst.sh -f 9027@kfi -t 9026@kfi -d 1:1 -m read -c 32 -n 1 -C simple
Discover server NIDs
Discover client NIDs
Start LST read - Fri 15 Nov 2024 12:47:58 PM CST
LST_SESSION=225541
SESSION: lnet_session FEATURES: 1 TIMEOUT: 300 FORCE: No
Adding clients: 9027@kfi
9027@kfi are added to session
Adding servers: 9026@kfi
9026@kfi are added to session
Test: --batch brw_read --concurrency 32 --from clients --to servers --distribute 1:1 brw read check=simple size=1m
Stat: --count 1 --delay 15 --bw --mbs clients servers
Test was added successfully
brw_read is running now
[LNet Bandwidth of clients]
[R] Avg: 18797.21 MB/s Min: 18797.21 MB/s Max: 18797.21 MB/s
[W] Avg: 2.87 MB/s Min: 2.87 MB/s Max: 2.87 MB/s
[LNet Bandwidth of servers]
[R] Avg: 2.87 MB/s Min: 2.87 MB/s Max: 2.87 MB/s
[W] Avg: 18797.90 MB/s Min: 18797.90 MB/s Max: 18797.90 MB/s
1 batch in stopping
Batch is stopped
Stop LST read - Fri 15 Nov 2024 12:48:14 PM CST
session is endedOn huygens, nid[509-511] to nid512 3:1 BW:
WRITES:
nid509:~ # lst.sh -f "9027@kfi 9026@kfi 9155@kfi" -t 9154@kfi -d 3:1 -m write -c 32 -n 1 -C simple
Discover server NIDs
Discover client NIDs
Start LST write - Fri 15 Nov 2024 12:45:30 PM CST
LST_SESSION=225511
SESSION: lnet_session FEATURES: 1 TIMEOUT: 300 FORCE: No
Adding clients: 9027@kfi 9026@kfi 9155@kfi
9027@kfi are added to session
9026@kfi are added to session
9155@kfi are added to session
Adding servers: 9154@kfi
9154@kfi are added to session
Test: --batch brw_write --concurrency 32 --from clients --to servers --distribute 3:1 brw write check=simple size=1m
Stat: --count 1 --delay 15 --bw --mbs clients servers
Test was added successfully
brw_write is running now
[LNet Bandwidth of clients]
[R] Avg: 2.40 MB/s Min: 2.40 MB/s Max: 2.40 MB/s
[W] Avg: 15743.83 MB/s Min: 15732.86 MB/s Max: 15756.41 MB/s
[LNet Bandwidth of servers]
[R] Avg: 47232.89 MB/s Min: 47232.89 MB/s Max: 47232.89 MB/s
[W] Avg: 7.21 MB/s Min: 7.21 MB/s Max: 7.21 MB/s
3 batch in stopping
Batch is stopped
Stop LST write - Fri 15 Nov 2024 12:45:46 PM CST
session is endedREADS:
nid509:~ # lst.sh -f "9027@kfi 9026@kfi 9155@kfi" -t 9154@kfi -d 3:1 -m read -c 32 -n 1 -C simple
Discover server NIDs
Discover client NIDs
Start LST read - Fri 15 Nov 2024 12:48:50 PM CST
LST_SESSION=225567
SESSION: lnet_session FEATURES: 1 TIMEOUT: 300 FORCE: No
Adding clients: 9027@kfi 9026@kfi 9155@kfi
9027@kfi are added to session
9026@kfi are added to session
9155@kfi are added to session
Adding servers: 9154@kfi
9154@kfi are added to session
Test: --batch brw_read --concurrency 32 --from clients --to servers --distribute 3:1 brw read check=simple size=1m
Stat: --count 1 --delay 15 --bw --mbs clients servers
Test was added successfully
brw_read is running now
[LNet Bandwidth of clients]
[R] Avg: 6266.42 MB/s Min: 44.16 MB/s Max: 18656.51 MB/s
[W] Avg: 0.96 MB/s Min: 0.01 MB/s Max: 2.85 MB/s
[LNet Bandwidth of servers]
[R] Avg: 2.87 MB/s Min: 2.87 MB/s Max: 2.87 MB/s
[W] Avg: 18798.31 MB/s Min: 18798.31 MB/s Max: 18798.31 MB/s
1 batch in stopping
Batch is stopped
Stop LST read - Fri 15 Nov 2024 12:49:10 PM CST
session is ended